

INTRODUCTION
Large language models (LLMs) such as ChatGPT, Google Gemini, and Claude are learning models designed to process and produce natural language in response to user input (Shen, Heacock, Elias, et al. 2023). LLMs are built on the transformer architecture, a neural network-based architecture that uses a self-attention mechanism to extract relevant context and produce compelling responses to human inputs, even in tasks for which it was not specifically trained (Li et al., n.d.). While neural networks have been discussed for many decades and the transformer was invented in 2017 (Li et al., n.d.), the LLM reached public prominence with the release of ChatGPT in 2022 (Grudin 2023). In recent years, there has been an increase in the development of LLMs which has led to a surge in the investigation of their utility in various fields. Of note, the potential role of LLMs in medicine is an avenue of active exploration (Park, Pillai, Deng, et al. 2024; Shah, Entwistle, and Pfeffer 2023; Clusmann, Kolbinger, Muti, et al. 2023; De Angelis, Baglivo, Arzilli, et al. 2023).
The most extensively researched LLM in medicine is Chat Generative Pre-trained Transformer, widely known as ChatGPT. The standard ChatGPT version utilizes GPT 3.5 which contains over 550 gigabytes of information from articles, websites, and journals to generate responses to human input (Shen, Heacock, Elias, et al. 2023). ChatGPT 4 is an updated version, released in March 2023, and has been trained to allow visual and audio user inputs as well as text. While studies of ChatGPT 4’s performance are ongoing, ChatGPT 3.5 has recently been shown to pass Step 1 of the United States Medical Licensing Exam and has been studied for performance in ophthalmology, dermatology, and radiology board-style examination questions (Gilson, Safranek, Huang, et al. 2023; Joly-Chevrier et al. 2023; Antaki et al., n.d.; “Performance of ChatGPT on a Radiology Board-Style Examination: Insights into Current Strengths and Limitations,” n.d.). Previous studies of ChatGPT 3.5 and 4 performance on Orthopaedic Surgery In-Training Exam (OITE) written board questions have shown that ChatGPT 3.5 is capable of performing at the level of a PGY-1 resident, and ChatGPT 4 approximately between the level of a PGY-2 and PGY-3 resident (Jain et al. 2024; Hofmann, Guerra, Le, et al. 2024).
Importantly, there are currently no studies comparing the performance of other current LLMs on OITE questions to each other and orthopedic trainees. With the rapidly developing world of artificial intelligence, this provides a good opportunity to determine which LLM is most accurate on OITE performance and therefore most likely to aid in future orthopedic training. Our study aims to compare the performance of Chat GPT 3.5, Chat GPT 4, Google Gemini, and Claude on OITE questions from the 2022 OITE Exam against each other and orthopedic residents.
We hypothesize that the newer LLMs such as Open AI’S ChatGPT 4, Google’s updated Gemini (formerly BARD) as well as Anthropic’s Claude, which have image recognition features, will outperform ChatGPT 3.5 in a head-to-head analysis. Additionally, we postulate that these newer LLMs with image recognition will reach the accuracy of PGY-4 orthopaedic surgery residents and build on the previous success of LLMs up to the PGY-3 level. This raises philosophical questions as to what intelligence is and the utility of artificial intelligence in not only answering written board-style questions, but their utility in diagnosing, treating, and prognosticating patients with orthopaedic pathologies in the near future. If the trajectory of artificial intelligence continues, year-by-year we will continue to see improvements in its ability to answer orthopaedic questions, eventually likely reaching or exceeding the level of fellowship-trained orthopaedic surgeons in the near future.
MATERIALS AND METHODS
A complete set of questions from the OITE 2022 exam was inputted into four different LLMs: ChatGPT 3.5, ChatGPT 4, Google Gemini, and Claude. A simple prompt explaining the goal of the questioning was inputted prior to asking the question, for each question. The prompt was as follows: “A question from the Orthopaedic In-Training Exam will be provided to you along with 4 answer choices. Select only one correct answer along with an explanation & source of the explanation.” The chat was reset each time before entering the prompt again for a new question.
The answers from each LLM were recorded, tabulated, and the percentage correct was calculated and compared against postgraduate year one through five (PGY-1 to PGY-5) orthopaedic surgery residents from ACGME-accredited residency programs. Three different types of questions were asked of four AI tools. Type A questions related to knowledge and recall of facts, Type B questions involved diagnosis and analysis of information, and Type C questions focused on the evaluation and management of diseases, requiring knowledge and reasoning to develop treatment plans. An example of a Type B question with an image and response from Claude is shown in Figures 1 and 2.

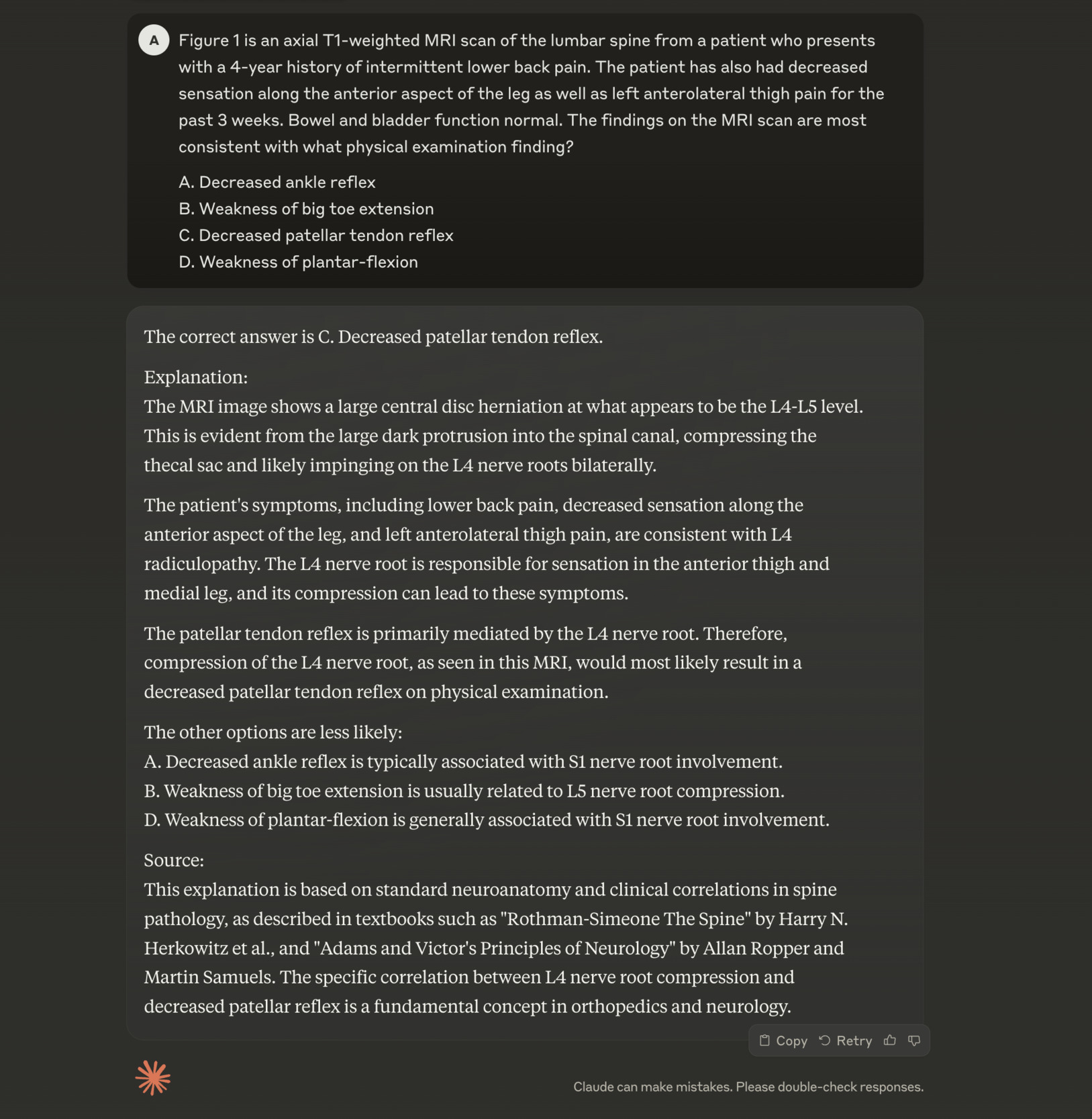
This example question was selected because imaging other than plain film x-rays seem to be harder for LLMs and trainees to interpret at a general level and in this case, Claude was able to accurately interpret the information, give the correct answer, and cite a verified source.
Data regarding resident performance nationally was obtained from the American Academy of Orthopaedic Surgeons OITE 2022 technical report. The OITE written board questions utilized in this study are copyrighted by the American Academy of Orthopaedic Surgeons (AAOS) ResStudy tool and are not publicly accessible.
Statistical Summary Method
The collected data were summarized using SPSS (version 26) through the following steps:
Data Entry: Different items were input into SPSS, including variables for Question ID, AI Tool, presence of an image in the question, the type of question, and whether the answer was correct or incorrect.
Descriptive Statistics: Percentages of correct answers for each AI tool were calculated to summarize performance.
RESULTS
The breakdown of the question domain and percentages is reported in Table 1.
A total of 206 questions were asked of the AI tools: 65 (31.6%) were Type A questions, 42 (20.4%) were Type B questions, and 92 (44.7%) were Type C questions. The type for 7 (3.4%) questions was not determined (Table 2). Table 3 represents the average scores of orthopaedic surgery residents nationally.
Gemini was the most accurate AI tool, correctly answering 144 questions (69.9%). Claude followed closely with 140 correct answers (68%), while ChatGPT 4 correctly answered 129 questions (62.6%). ChatGPT 3.5 correctly answered 120 questions (58.3%) (Table 4).
Of all questions, 80 (38.8%) questions included images, while the remaining 126 (61.2%) did not. The AI tools showed a higher rate of correct answers for questions without images compared to those with images (65.9% vs. 34.1%) (Table 5).
Statistical summary indicated that the difference was primarily due to ChatGPT 3.5, which had the weakest performance. In terms of questions with images, Google Gemini was the most accurate AI tool with 60% correct answers, followed by Claude, ChatGPT 4 (each with 57.5%), and ChatGPT 3 (52.5%) (Table 6).
Gemini also performed the best on questions without images, with 76.2% correct answers, followed by Claude (75.2%), ChatGPT 4 (65.9%), and ChatGPT 3.5 (61.9%) (Table 7).
Type A Questions: Gemini was the most accurate AI tool with 76.9% correct answers, followed by Claude (69.2%). ChatGPT 4 and ChatGPT 3.5 correctly answered 60.0% and 56.9% of questions, respectively (Table 8).
Type B Questions: Claude was the most accurate AI tool with 70.7% correct answers, followed by ChatGPT 3.5 (69.0%). Gemini and ChatGPT 4 correctly answered 61.9% and 54.8% of questions, respectively (Table 8).
Type C Questions: Gemini was the most accurate AI tool with 67.4% correct answers, followed by ChatGPT 4 (66.3%). Claude and ChatGPT 3.5 correctly answered 65.2% and 52.2% of questions, respectively (Table 8).
DISCUSSION
LLMs are disrupting technologies that have immense potential to understand and synthesize large amounts of information and present it in various modalities (e.g. tabulated, narrative, bullet point, etc). One such application of LLMs has been on various medical speciality board exams, where their performance has begun to meet and exceed the expected standards (Gilson, Safranek, Huang, et al. 2023; Joly-Chevrier et al. 2023; Antaki et al., n.d.; “Performance of ChatGPT on a Radiology Board-Style Examination: Insights into Current Strengths and Limitations,” n.d.; Jain et al. 2024; J. E. Kung et al., n.d.; T. H. Kung, Cheatham, Medenilla, et al. 2023; Labouchère and Raffoul 2024; Fowler, Pullen, and Birkett 2023; Humar et al. 2023; Ghanem et al. 2023; Ali, Tang, Connolly, et al. 2023; Oh, Choi, and Lee 2023).
The recent study by Kung et al. found that the newer ChatGPT 4 model performed better than the average PGY-5 orthopaedic surgery resident. However, this study has a question pool that was three times larger than ours, and unlike our study did not upload supplementary images or radiographic imaging. Our study demonstrated a higher accuracy with ChatGPT 3.5 (58.3%) as compared to the study by Kung et al. (51.6%). Our study included a simple prompt while the study by Kung et al. did not include any prompting, which may explain our higher percentage of correct answers with Chat GPT 3.5 on the 2022 OITE. Utilizing ChatGPT 4, our results demonstrated an accuracy of 62.6% vs Kung et al.'s 73.4% correct. This discrepancy may have been due to the larger number of questions in Kung et al.'s study, which can result in supervised learning of the LLM and greater accuracy with an increasing number of questions entered in a given chat without resetting for each input as we did (J. E. Kung et al., n.d.; Sarker 2022). Our results demonstrated that Google Gemini was the most accurate (69.9%) which rivaled the 73.4% correct in the study by Kung et al.
Contrary to our expectations, questions without images were answered with greater accuracy as opposed to questions with images (65.9% vs. 34.1%, respectively). There may be various reasons for this such as the complexity of image recognition, training model data limitations, the difficulty of questions with images, and ambiguous or low-quality images (Poon and Sung 2021). Moreover, as image recognition is a relatively newer feature of LLMs, there is still a facet of user learning and user input analysis that needs to be done in order for these programs to consistently and accurately interpret orthopaedic images. The novelty of these features could have contributed to the increased error rate and incorrect answers from the LLMs for questions with figures and/or images.
Nevertheless, our results corroborate previous research on the utility and accuracy of LLMs on various board exams including the written orthopaedic surgery board exam (i.e. OITE). Most importantly, all LLMs performed above the average of an orthopaedic surgery intern (Table 1).
Having said this, integrating these tools with healthcare represents numerous challenges that must be recognized, addressed, and mitigated such as when it comes to protected health information security, and hallucinations of LLMs (Lisacek-Kiosoglous et al. 2023). Among these challenges of relevance to the realm of orthopedic education is the potential for misuse of LLMs on the OITE by examinees. More infrastructural cybersecurity needs to be built to prevent this from occurring, and as AI advances, the world of cybersecurity is projected to make strides similarly (Radanliev and De Roure 2022). Although completely autonomous clinical decision-making is not yet a reality in orthopaedic surgery, the current trends present a promising opportunity to integrate human and machine to improve education, patient care, and outcomes. LLMs have been shown to have the potential to optimize patient selection and safety, improve diagnostic imaging efficiency, and analyze large patient datasets (Huffman, Pasqualini, Khan, et al., n.d.). On the inpatient medicine side, LLMs are being used in the prediction and management of diabetes (Nomura et al. 2021). In terms of surgical training, LLMs have the potential to analyze the technique of residents and generate feedback in a formative manner (Guerrero et al. 2023). LLMs have been explored as reliable teaching assistants in plastic surgery residency programs showing 100% interobserver agreement for the content accuracy, usefulness, and accuracy of AI-generated interactive case studies for residents, simulation of preoperative consultations, and ethical consideration scenarios (Mohapatra, Thiruvoth, Tripathy, et al. 2023). One can imagine how these tools can be used similarly in orthopaedic residency education and create an avenue of exploration to do so.
Limitations of this study include a small question set and inability to test each GPT that exists on the web. Additionally, images were not always reliably received by the LLMs with error messages occasionally popping up causing re-inputs of questions which may affect response. The prompt itself could have affected the response of LLMs to questions. The number of error messages that were received by LLMs after inputting an OITE question is an important metric to track that should be included in future studies as this demonstrates the relative performance of each program. Future work must also analyze how prompt engineering influences LLM responses to medical questions such as those of the OITE, how AI may be used in medical education, and how to safely and ethically implement these technologies. Furthermore, as our study included resident performance based on the AAOS technical report, we were unable to stratify resident performance on the 2022 OITE based on question type (A, B, or C) and compare this to LLM performance. This stratification would be important to include in future works as it can display gaps in the education process in comparison to the quality of LLMs.
CONCLUSION
The study assessed LLMs like Google Gemini, ChatGPT, and Claude against orthopaedic surgery residents on the OITE. Results showed that these LLMs perform on par with orthopaedic surgery residents, with Google Gemini achieving best performance overall and in Type A and C questions while Claude performed best in Type B questions. LLMs have the potential to be used to generate formative feedback and interactive case studies for orthopaedic trainees.